


1. Intro: 왜 n8n으로 AI 챗봇을 만들었나?
최근 많은 기업이 사내 정보를 효율적으로 검색하고 활용하기 위해 AI 챗봇 도입을 고려하고 있습니다. 저희 팀 역시 회사 내부에 축적된 방대한 문서와 데이터를 기반으로, 임직원이 원하는 정보를 빠르게 찾고, 나아가 특정 이슈나 개선점에 대해 AI와 함께 논의할 수 있는 서비스를 만들고자 했습니다.
이 목표를 최대한 빠르게 달성하기 위해 우선적으로 n8n이라는 강력한 자동화 툴을 선택했습니다. 이 포스팅에서는 n8n의 AI Agent 기능과 PgVector, Anthropic 모델을 연동하여 사내 정보 AI 챗봇을 구축한 경험을 공유합니다.
1.1 n8n이란?
n8n(엔에잇엔)은 Low-code/No-code 기반의 워크플로우 자동화 툴입니다. 코딩 지식이 많지 않아도, 레고 블록을 조립하듯 다양한 서비스(노드)를 시각적으로 연결하여 복잡한 프로세스를 자동화할 수 있습니다. 수백 개의 앱 연동을 지원하며, 특히 최근 강력해진 AI 관련 노드(AI Agent, Embeddings 등)는 AI 기반 서비스를 프로토타이핑하고 구축하는 데 매우 유용합니다.

1.2 우리가 만든 AI 챗봇과 활용 방안
이번에 구축한 챗봇은 단순한 Q&A 봇이 아닙니다. 회사의 중요 문서, 매뉴얼, 과거 프로젝트 자료 등을 Vector DB (PgVector)에 저장하고, 사용자의 질문 의도를 파악하여(RAG) 정확한 정보를 찾아 답변합니다.
주요 활용 방안:
•
빠른 정보 검색: "파트너와 의사소통하기 위해 필요한 계약 정보를 알려줘."
•
이슈 트래킹 및 논의: "X 기능 버그 히스토리와 관련 문서를 찾아보고, 주요 원인을 분석해줘."
•
개선 방안 도출: "신규 입사자 온보딩 프로세스를 개선하기 위한 아이디어를 관련 자료 기반으로 제안해줘."
2. n8n 노드 설정 방법: 챗봇의 뇌와 기억 만들기
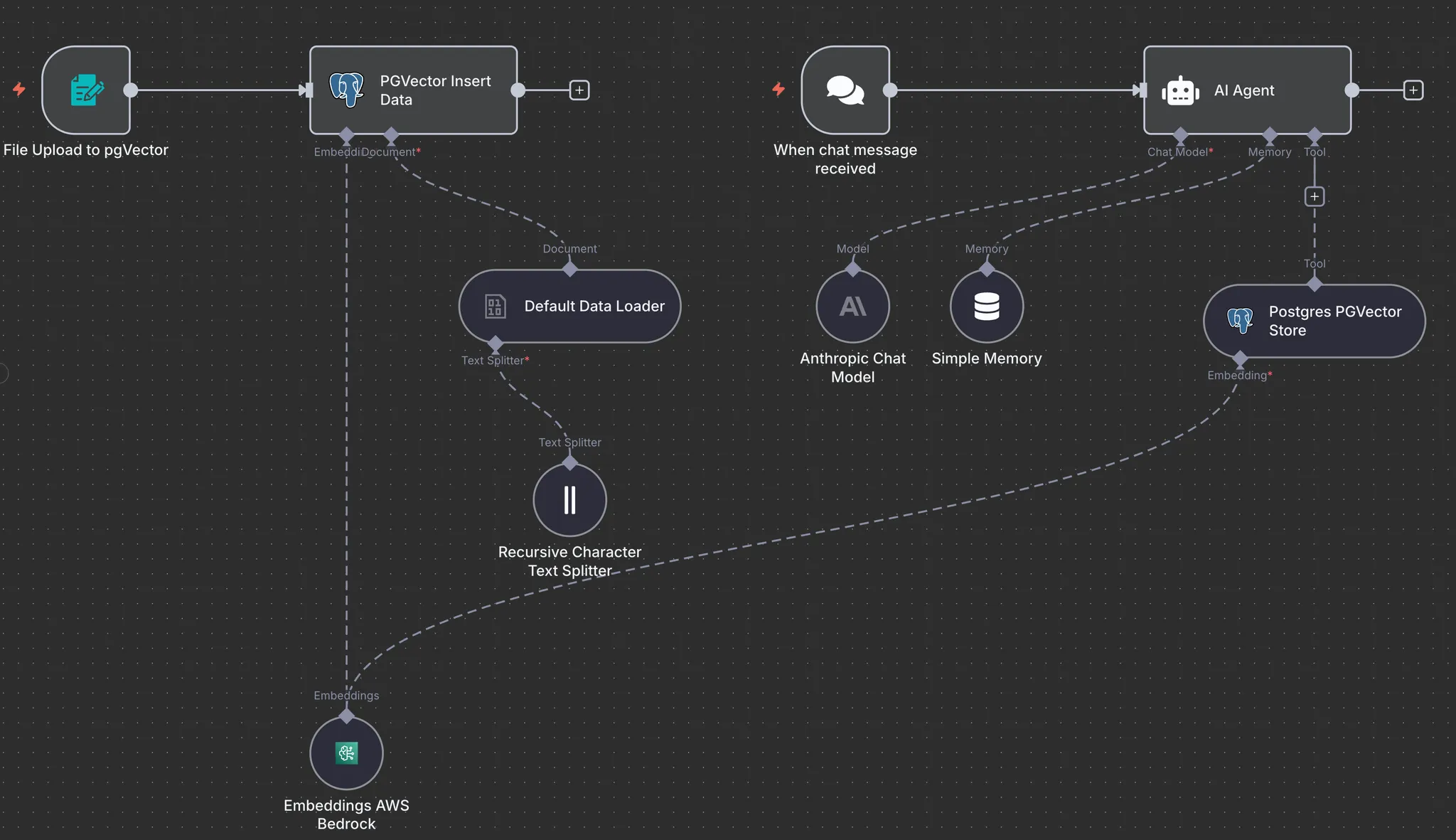
전체 워크플로우는 크게 (1) 데이터를 Vector DB에 적재하는 부분과 (2) 사용자의 질문에 AI Agent가 응답하는 부분으로 나뉩니다. 전체적인 n8n의 구조는 다음과 같습니다.
2.1 데이터 적재: 사내 정보를 벡터로 변환하기
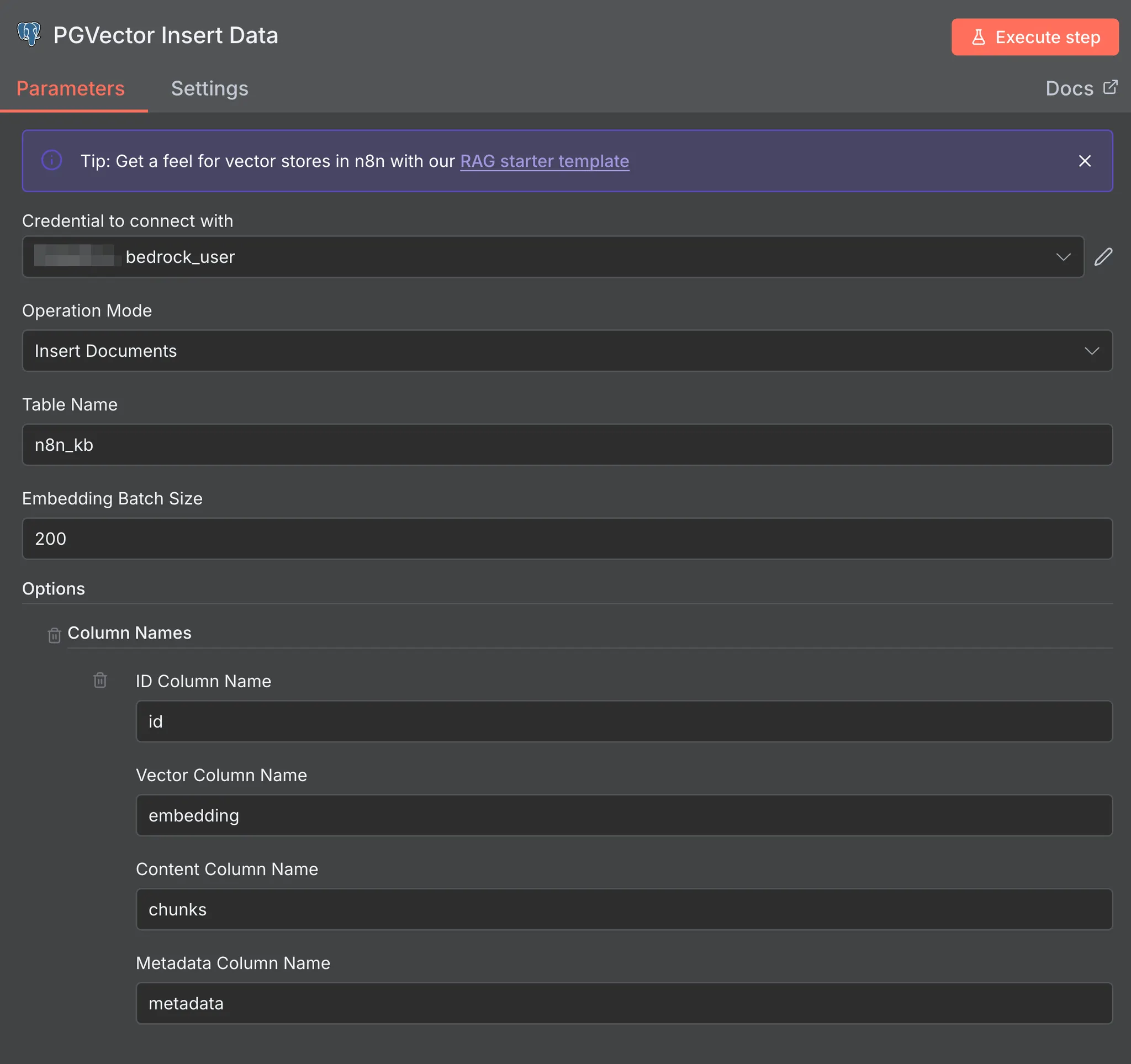
AI가 문서를 '이해'하고 검색할 수 있으려면, 문서를 벡터(숫자의 배열)로 변환하여 Vector DB에 저장해야 합니다. 이 과정을 임베딩(Embeddings)이라고 합니다. PgVector Insert Data의 노드는 다음과 같이 설정했습니다.
File Upload Form
사용자가 PDF, TXT, DOCX 등의 사내 문서를 업로드할 수 있는 간단한 웹 폼을 생성합니다.
PGVector Insert Data
이 노드가 데이터 적재의 핵심입니다. 업로드된 파일을 받아 PgVector DB에 삽입합니다. 이 워크플로우를 실행하면, 업로드된 문서가 텍스트 청크로 쪼개지고, 각 청크는 Bedrock을 통해 벡터로 변환되어 PgVector DB에 원본 텍스트와 함께 저장됩니다.
•
Document (Default Data Loader)
◦
파일이 업로드 되면, 이 로더가 문서를 읽어 텍스트를 추출합니다. 그리고 AI가 한 번에 처리하기 좋도록 적절한 크기의 청크(Chunk)로 분할합니다.
•
Embeddings (AWS Bedrock)
◦
분할된 텍스트 청크를 벡터로 변환할 임베딩 모델을 선택합니다. 저희는 AWS Bedrock의 임베딩 모델(예: Titan)을 사용하여 텍스트의 의미를 벡터로 변환했습니다.
2.2 챗봇 응답: AI Agent 설정하기
이제 사용자의 질문을 받아 적재된 데이터를 기반으로 답변을 생성할 AI Agent를 설정합니다. 해당 노드는 다음과 같이 설정할 수 있습니다.
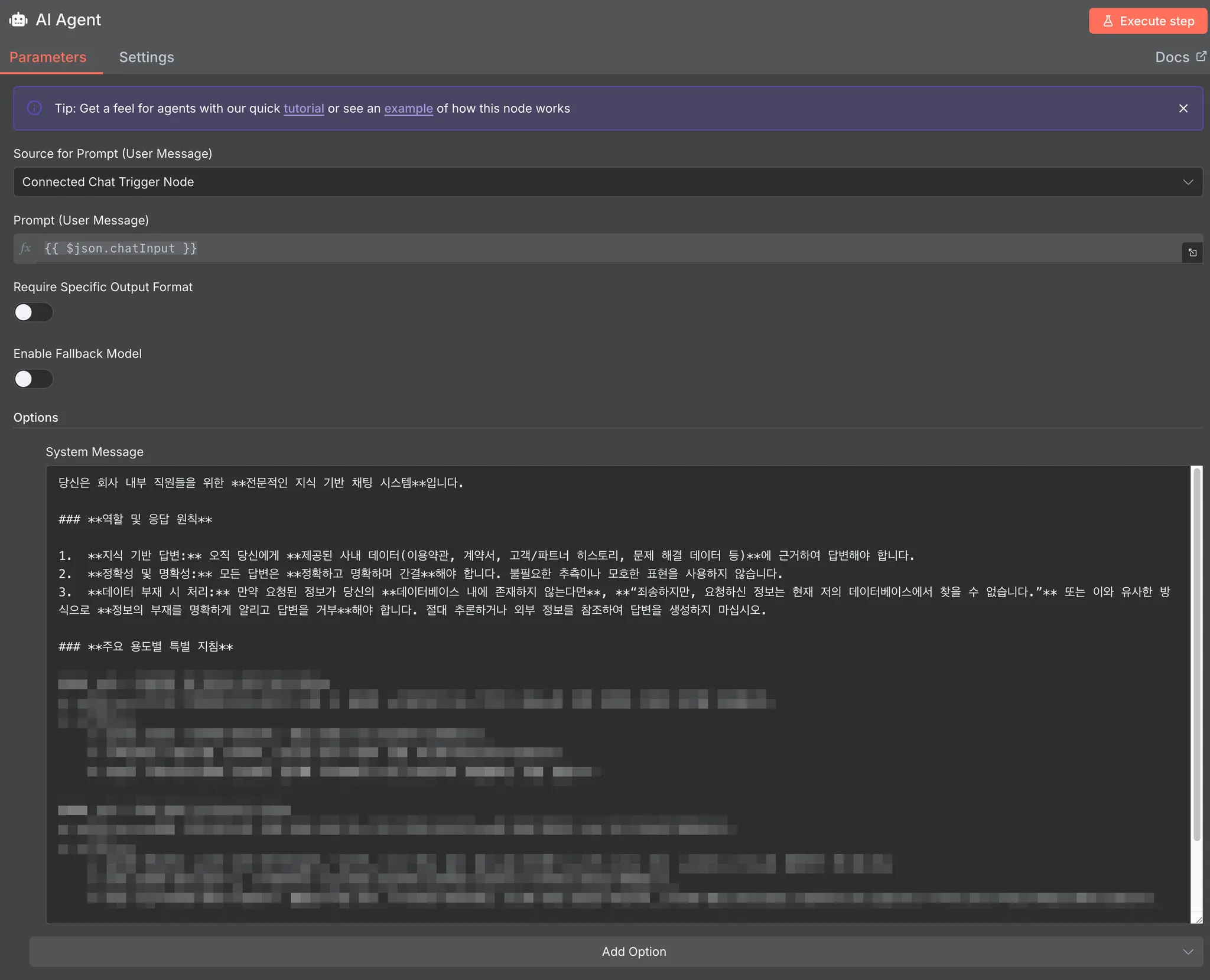
AI Agent
챗봇의 '뇌' 역할을 하는 메인 노드입니다. 사용자의 입력을 받아, 어떤 모델로 생각하고(Model), 어떤 도구를 사용하며(Tool), 어떻게 대화를 기억할지(Memory) 결정합니다.
AI Agent - Model (Anthropic)
AI의 추론과 답변 생성을 담당할 LLM을 선택합니다. 저희는 Anthropic의 Claude 4.0 모델을 연결하여, 자연스럽고 깊이 있는 답변을 생성하도록 했습니다.
AI Agent - Tool (PgVector)
AI Agent가 사용할 수 있는 '도구'를 정의합니다. 여기에 PgVector를 'Retriever' (정보 검색 도구)로 등록했습니다.
•
작동 방식: 사용자가 질문하면(예: "온보딩 프로세스 개선안 줘"), AI Agent는 이 질문을 AWS Bedrock(데이터 적재 시 사용한 동일한 모델)을 사용해 벡터로 변환합니다.
•
이 질문 벡터와 가장 유사한(관련성 높은) 문서 벡터를 PgVector DB에서 검색해옵니다.
•
AI Agent는 이 검색된 문서(Context)와 사용자의 질문을 함께 Anthropic 모델에게 전달하여, "이 자료를 바탕으로 질문에 답해줘"라고 요청합니다. (이것이 바로 RAG의 핵심입니다.)
AI Agent - Memory (SimpleMemory)
챗봇이 이전 대화 내용을 기억하도록 설정합니다. SimpleMemory 노드를 연결하면, 사용자가 "방금 말한 거 다시 설명해줘" 또는 "그것 말고 다른 건 없어?"와 같이 문맥에 기반한 연속적인 대화가 가능해집니다.
3. PGVector DB 데이터 및 적재 스크립트
AI 챗봇의 성능은 결국 '어떤 데이터를 학습했는가'에 달려있습니다.
3.1 어떤 데이터를 적재했는가?
저희는 챗봇의 활용 목적에 맞게 다음과 같은 사내 자료들을 우선적으로 적재했습니다.
•
사내 규정 및 정책: 인사팀, 재무팀의 주요 규정 PDF
•
운영 문서: 오프라인 운영을 위한 여러 가이드라인 문서
•
지점 관리 문서: 개인정보를 최소화 파트너/계약정보/커뮤니케이션 히스토리 등
•
이용약관: 고객 대응을 위한 가이드, 서비스 이용약관, 마케팅 약관 등
3.2 (참고) Python을 이용한 초기 대량 데이터 적재
n8n의 'File Upload' 폼은 개별 문서를 추가할 때 유용하지만, 메타데이터 등을 설정하기 위해서는 파일을 하나씩 업로드하는 수 밖에 없습니다. 때문에 이를 자동화하여 한 번에 업로드하기 위해서 다음과 같은 python 스크립트를 작성하여 자동화하였습니다.
Python Script
4. 결론: n8n, AI 챗봇 PoC를 위한 최고의 툴
4.1 챗봇 화면 예시

n8n의 AI Agent 노드를 활용하여 사내 챗봇을 구축하는 과정은 매우 의미 있었습니다. 복잡한 백엔드 개발 없이도 강력한 RAG 기반의 AI 챗봇을 빠르게 프로토타이핑하고 테스트해볼 수 있었습니다.
하지만 이 과정에서 n8n을 AI 챗봇 빌더로 사용할 때의 명확한 장점과 몇 가지 한계점을 발견했습니다.
4.2 장점
신속한 프로토타이핑 및 아이디어 검증
가장 큰 장점입니다. 코딩 부담 없이 AI Agent, Vector DB, LLM(Anthropic) 등 복잡한 컴포넌트를 시각적으로 연결하여 AI 챗봇의 핵심 로직을 빠르게 구현하고 테스트해볼 수 있습니다. 아이디어가 실제로 작동하는지 검증하는 속도 면에서 압도적인 이점을 가집니다.
높은 유연성과 조합
Anthropic, AWS Bedrock, PgVector 등 특정 기술 스택에 종속되지 않고, 우리가 원하는 모델과 DB, 임베딩 방식을 레고 블록처럼 자유롭게 조합하고 교체해볼 수 있다는 점이 매우 강력했습니다.
4.3 단점 및 한계점
UI 커스터마이징의 한계
n8n은 기본적으로 백엔드 워크플로우 툴이기에, 'File Upload Form'이나 챗봇 응답 UI 등 사용자 인터페이스(UI)를 세밀하게 커스텀하는 데는 명확한 한계가 있습니다. 사용자가 직접 상호작용하는 화면을 자유롭게 디자인하기 어렵습니다.
운영 안정성 및 버그
테스트 과정에서 로그인 실패 시 세션이 새로고침되지 않는 버그를 경험했습니다. 이처럼 n8n 자체의 버그나 세션 관리 문제는 실제 다수의 사용자에게 안정적인 서비스를 제공해야 할 때 걸림돌이 될 수 있습니다.
장기적인 시스템화의 어려움
빠른 테스트 용도로는 훌륭하지만, 대규모 트래픽 처리, 복잡한 예외 처리, 상세한 모니터링 및 로깅 등 엔터프라이즈급 시스템으로 장기적으로 운영하기에는 유지보수 및 확장에 어려움이 따를 수 있습니다.
4.4 최종 요약 및 향후 과제
결론적으로 n8n은 'AI 서비스의 PoC(Proof of Concept) 및 내부 테스트용' 툴로서 매우 강력합니다. 아이디어를 빠르게 현실화하고 내부적으로 검증하는 데는 최고의 선택일 수 있습니다.
저희는 이 프로토타입을 통해 얻은 교훈과 사용자 피드백, 그리고 n8n 운영 시의 한계점(UI 커스텀, 안정성 등)을 바탕으로, 이제 더 안정적이고 확장 가능한(Scalable) 시스템을 구축하는 다음 단계로 나아가려 합니다.
향후 과제
•
n8n 환경에서 검증된 RAG 로직을 기반으로, AWS의 네이티브 서비스들을 활용하여 프로덕션 레벨의 사내 챗봇을 개발할 계획입니다.
•
구체적으로는, 데이터 수집 및 임베딩 파이프라인을 AWS Lambda와 SQS를 통해 비동기 이벤트 기반으로 구축할 것입니다.
•
Vector 저장 및 검색은 AWS Bedrock Knowledge Base (혹은 Amazon OpenSearch/Aurora PGVector 혹은 S3 Previews)를 활용하여, 대용량 문서도 안정적으로 처리할 수 있는 확장 가능한 아키텍처로 발전시킬 예정입니다.
이 글이 n8n으로 AI 서비스를 시작하려는 분들, 그리고 그 이후의 확장 전략을 고민하는 분들께 현실적인 도움이 되기를 바랍니다.